
교수님의 조언: e.x. 말고, e.g. 쓰기 / 수식 아래 각각의 매개변수 의미 쓰기 / mn 초코 말고 mn 가로 세로 해상도인 것 잊지 말기
✨ e.g. (exempli gratia) – “예를 들어”
- 여러 가지 예시 중 일부를 제시할 때 사용
- “for example”과 같은 의미
- 모든 예시를 포함하지 않음!
비디오 코텍 성능
우리는 비디오 인코더가 비디오 프레임 시퀀스를 압축하여 인코딩된 비트스트림(encoded bitstream)을 생성하는 과정과, 비디오 디코더가 비트스트림을 복원하여 디코딩된 비디오 시퀀스(decoded video sequence)를 생성하는 과정을 살펴보았다. 대부분의 소비자용 비디오 코덱은 손실 압축(lossy compression)을 사용하므로, 디코딩된 비디오는 원본 비디오와 동일하지 않다. 일반적으로 인코더는 양자화(quantisation) 과정에서 정보 손실을 유발하며, 한 번 양자화된 데이터는 복원할 수 없다. 비디오 코덱의 성능, 즉 비디오를 얼마나 효율적으로 압축할 수 있는지는 다음 세 가지 주요 측면에서 평가할 수 있다.
- 압축률(Compression) 또는 비트율(Rate)
- 비디오가 얼마나 압축되는가?
- 압축된 비디오 파일을 저장하는 데 필요한 공간은 얼마인가?
- 압축된 비디오를 전송하기 위해 필요한 비트레이트(bitrate)는 얼마인가?
- 연산 복잡도(Computation)
- 인코딩 또는 디코딩 과정이 얼마나 복잡한가?
- 특정 프로세서에서 실시간(real-time) 인코딩/디코딩이 가능한가?
- 인코딩 또는 디코딩 시 얼마나 많은 메모리(RAM 등)가 필요한가?
- 인코딩 또는 디코딩이 소비하는 전력은 얼마나 되는가?
- 화질(Quality) 또는 왜곡(Distortion)
- 디코딩된 비디오는 어떻게 보이는가?
- 원본과 구별할 수 없을 정도로(visually lossless) 높은 품질을 유지하는가?
- 블록 노이즈(blockiness/block noise)나 블러(blurring) 같은 왜곡이 있는가?
- 디코딩된 비디오는 부드럽게 재생되는가, 아니면 끊기는가?
- 해당 애플리케이션에서 충분히 좋은 품질을 제공하는가?
비디오 코덱을 비교하거나 새로운 비디오 코딩 표준을 개발할 때 제안된 개선 사항을 포함할지를 결정하는 과정에서, 레이트-디스토션(Rate-Distortion, R-D) 성능을 측정하는 것이 일반적이다. 이는 다양한 압축 비트레이트(compressed bitrate)에서 디코딩된 비디오 품질을 비교하는 방식이다.
비디오 품질과 비트레이트 간의 관계는 레이트-디스토션 곡선(rate-distortion curve)으로 표현된다. 일반적으로 ‘더 나은’ 코덱이나 인코딩 기법은 다양한 비트레이트에서 더 높은 품질의 디코딩된 비디오를 생성할 수 있다. 그림의 예시에서는 Codec 1이 Codec 2보다 모든 테스트된 비트레이트에서 더 좋은 성능을 보인다.
그러나, 이 그림은 연산 성능(computational performance)을 보여주지 않는다. 일반적으로 더 나은 레이트-디스토션 성능을 제공하는 코덱은 인코더 또는 디코더, 혹은 둘 다에서 연산량이 증가하는 대가를 치를 가능성이 높다. 예를 들어, 적절한 인코딩 설정을 선택하면 H.265/HEVC 인코더는 H.264/AVC 인코더보다 훨씬 더 나은 레이트-디스토션 성능을 가질 수 있지만, 그 대가로 연산량이 증가할 수 있다.
비트레이트(압축된 파일 크기)는 비교적 쉽게 측정할 수 있다. 비디오의 비트레이트(Bitrate)는 초당 데이터 전송량을 나타내며, 다음과 같은 공식으로 계산된다.
비트레이트 계산 공식
Bitrate (bps) = 해상도 (Width × Height)×프레임레이트 (FPS)×비트 깊이 (Bit Depth)×색상 채널 수 (Ch)
- Bitrate (bps): 비트레이트 (비트 단위 per second)
- 해상도 (Width × Height): 영상의 가로 픽셀 수 × 세로 픽셀 수
- 프레임레이트 (FPS): 초당 프레임 수 (Frames Per Second)
- 비트 깊이 (Bit Depth): 각 픽셀의 색상 표현 비트 (예: 8-bit, 10-bit, 12-bit 등)
- 색상 채널 수 (Ch): RGB 영상의 경우 3 (YUV 4:2:0 압축에서는 Y=1, U=0.5, V=0.5)
압축을 적용한 비트레이트 공식
실제 전송 비트레이트는 압축 코덱(예: H.264, H.265, AV1 등)에 따라 크게 감소하므로, 압축 비율(Compression Ratio, CR)을 고려해야 한다.
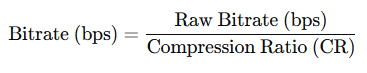
- Compression Ratio (CR): 압축률
- 인코딩된 비트 수를 초당 비디오 프레임 수로 나눈 값(즉, 인코딩 비트레이트)을 계산하거나,
- 인코딩된 비디오 파일의 전체 바이트 크기를 측정하면 된다.
연산량(Computation)도 비교적 쉽게 측정하거나 추정할 수 있다.
- 예를 들어, 전체 비디오 파일을 인코딩하는 데 걸리는 시간(초 단위)을 측정하면 된다.
그러나, 비디오 품질(Video Quality)을 평가하는 것은 훨씬 더 어려운 문제이다. “이 비디오는 얼마나 좋은가?”라는 질문은 본질적으로 주관적인 판단이기 때문이다.
Video Quality
시각적 품질(visual quality)을 측정하는 것은 어려운 과제이다. 그 이유는 품질이 주관적(subjective)이기 때문이다.
예를 들어, 두 사람에게 “이 비디오는 얼마나 좋아 보입니까?”라고 물어보면 서로 다른 답변을 받을 가능성이 높다.
심지어, 같은 사람이라도 상황에 따라 다른 답변을 할 수 있다.
비디오를 감상하는 환경, 비디오 콘텐츠, 개인의 경험, 그 당시의 감정 상태 등의 다양한 요인에 따라 평가가 달라질 수 있기 때문이다.
그렇다면 비디오 품질을 어떻게 측정할 수 있을까?
간단한 답변은 인간이 비디오의 품질을 어떻게 평가할지 완전히 측정하거나 예측하는 것은 불가능하다는 것이다.
하지만, 비디오 품질을 근사(approximate)하거나 추정(estimate)하는 방법은 존재하며, 크게 두 가지로 나눌 수 있다.
- 주관적 품질 측정(Subjective Quality Measurement)
- 인간 관찰자(human observers)에게 직접 비디오의 품질을 평가하도록 요청하는 방식이다.
- 사람마다 평가 기준이 다르므로, 관찰자 간의 자연스러운 의견 차이를 보정(compensate)하는 것이 목적이다.
- 객관적 품질 측정(Objective Quality Measurement)
- 수학적 계산을 통해 품질을 측정하는 방법이다.
- 사람의 주관적 평가(opinion)를 근사하는 품질 측정 지표(metric)를 계산하여 품질을 평가한다.
- 대표적인 객관적 품질 평가 지표로는 PSNR(Peak Signal-to-Noise Ratio), SSIM(Structural Similarity Index) 등이 있다.
즉, 주관적 방법은 인간의 실제 평가를 기반으로 하고, 객관적 방법은 이를 수학적으로 근사하는 방식이라고 할 수 있다.
주관적 품질 측정 (Subjective Quality Measurement)
주관적 품질에 영향을 미치는 요인 (Factors Influencing Subjective Quality)
우리의 시각적 장면에 대한 인지(perception)는 인간 시각 시스템(HVS, Human Visual System)의 다양한 요소(눈과 뇌 포함) 간의 복잡한 상호작용에 의해 형성된다.
비디오의 시각적 품질(visual quality)에 대한 인식은 다음과 같은 요인에 의해 영향을 받는다.
- 공간 충실도(Spatial Fidelity):
- 장면의 부분들이 얼마나 명확하게 보이는가?
- 눈에 띄는 왜곡(distortion)이 있는가?
- 시간적 충실도(Temporal Fidelity):
- 움직임(motion)이 자연스럽고 부드럽게 보이는가?
그러나, 관찰자의 품질 평가(opinion of quality)는 단순히 공간 및 시간적 충실도에만 영향을 받는 것이 아니다.
다음과 같은 요소들도 주관적 품질 평가에 중요한 영향을 미친다.
- 시청 환경(Viewing Environment):
- 예를 들어, 편안하고 방해 요소가 없는 환경에서 비디오를 감상하면, 영상 자체의 품질과 상관없이 더 높은 품질로 인식하는 경향이 있다.
- 관찰자의 상태(State of Mind)와 경험(Experience):
- 개인의 심리적 상태, 과거 경험, 비디오에 대한 관심도 등이 품질 평가에 영향을 미칠 수 있다.
- 시각적 주의(Visual Attention):
- 인간은 영상을 한 번에 전체적으로 인식하는 것이 아니라, 특정한 지점에 시선을 고정(fixation)하며 장면을 해석한다.
- 즉, 일부 중요한 부분만을 인지하며 전체 장면을 동시에 받아들이지는 않는다.
- 최신 기억 효과(Recency Effect):
- 시청자가 최근에 본 영상이 더 강한 영향을 미치는 경향이 있다.
- 즉, 전체 영상보다는 마지막 장면이나 최근 본 장면이 품질 평가에 더 큰 영향을 준다.
인간의 시각 정보 처리 한계
인간의 망막은 매우 많은 양의 시각 정보를 받아들이지만,
- 시각적 주의(attention)에 의해 초당 10kbits 미만의 정보만 처리할 수 있다.
- 따라서, 인간은 기억과 경험을 기반으로 시각적 장면을 보완(fill in)하여 해석한다.
즉, 실제로는 화면의 전체적인 세부 사항을 모두 인식하는 것이 아니라, 일부 선택된 정보만을 집중적으로 처리하는 것이다.
이처럼 여러 요인들이 복합적으로 작용하기 때문에,
→ 비디오의 시각적 품질을 정량적으로(quantitatively) 측정하는 것은 매우 어렵다.
PSNR(Peak Signal-to-Noise Ratio)

Mean Squared Error (MSE, 평균제곱 오차): 예측값과 실제값 간의 차이를 제곱하여 평균을 구한 값이다. 회기 분석과 신호 처리에서 모델의 성능을 평가하는 데 널리 사용된다.

2. MSE의 특징
✅ 항상 0 이상: MSE는 제곱을 하기 때문에 항상 0 이상이며, 0에 가까울수록 모델의 예측이 실제값과 유사함을 의미한다.
✅ 큰 오차에 민감: 오차가 클수록 제곱 값이 커지므로, MSE는 이상치(Outlier)에 민감하다.
✅ 단위 문제: MSE의 단위는 원래 값의 제곱 단위가 되어 해석이 직관적이지 않을 수 있다.
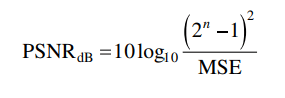
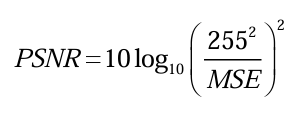

I는 원본 이미지 값, K는 비교 이미지 값이다. // i,j는 좌표값을 뜻한다. // m,n은 해상도, 가로, 세로를 뜻한다. // [ ]^2 제곱을 하는 이유는 차분 값이 음수일 수 있기 때문에 이를 방지하기 위함이다. // MAX는 영상의 최대 픽셀 값이다. //8bit 영상에 대한 PSNR은 2^8 = 256, 256-1 값인 255가 분자로 들어가는 식의 예시를 볼 수 있다.
IV-PSNR(Immersive Video Peak Signal-to-Noise Ratio)
1️⃣ 배경 (Background)
- 멀티뷰(Multi-view) 비디오에서 생성된 몰입형 비디오(Immersive Video)는 고유한 왜곡(distortions)을 유발할 수 있음.
- 여러 개의 카메라를 활용하여 비디오를 생성하면 픽셀 정렬 문제, 밝기 차이 등의 오류가 발생할 수 있음.
2️⃣ 해결하고자 하는 문제 (Challenges Addressed)
👉 (1) Corresponding Pixel Correction (대응 픽셀 보정)
- 가상 뷰 합성(Virtual View Synthesis) 과정에서 미세한 픽셀 불일치가 발생
- 인간의 눈으로는 감지하기 어렵지만, 픽셀 정렬이 완벽하지 않음.
- 이 문제를 해결하기 위해 지역적 5×5 블록에서 가장 유사한 픽셀을 탐색하여 보정함.
- 그림처럼, 특정 픽셀(파란색)과 가장 유사한 픽셀을 주변 5×5 블록 내에서 탐색하여 정렬 보정 수행.
👉 (2) Global Component Difference Correction (전역 구성 요소 차이 보정)
멀티 카메라 시스템에서는 전체적인 밝기(brightness) 및 색상(color) 차이가 발생할 수 있음. 평균적인 전역 차이(Global Average Difference)를 계산하여 보정. 이를 활용해 오류 계산을 조정하고, 보다 자연스러운 비디오 품질 유지.

📌 매개변수 설명
b: 비트 깊이(Bit Depth)를 나타냄. 예를 들어, 8비트 컬러 영상이라면 b=8, 10비트 컬러 영상이라면 b=10
2^b−1은 픽셀 값의 최대 범위를 나타냄. (예: 8비트 영상의 경우 255)
IV-MSE: Immersive Video Mean Squared Error (몰입형 비디오 평균 제곱 오차) 원본 영상과 복원된 영상 간의 픽셀 차이를 제곱하여 평균 낸 값. 값이 작을수록 두 영상의 차이가 적고, 품질이 더 좋음.
IV-PSNR: Immersive Video PSNR(신호 대 잡음비) 값이 클수록 화질이 좋으며, 낮을수록 화질이 나쁨.


🔹 블록 크기 선택의 유동성
1️⃣ 기본적으로 논문이나 연구에서 특정 크기(예: 5×5)를 사용하면, 해당 실험에서는 그 크기를 따르는 경우가 많음.
- 예제 이미지에서는 5×5블록이 사용되었지만, 다른 연구에서는 3×3, 7×7, 또는 가변 크기 블록을 사용할 수도 있음.
2️⃣ 블록 크기를 조정하는 이유:
- 더 작은 블록(예: 3×3)
→ 더 정밀한 픽셀 보정이 가능하지만, 잡음(noise)에도 민감할 수 있음. - 더 큰 블록(예: 7×7 이상)
→ 더 강력한 보정 효과를 줄 수 있지만, 연산 비용이 증가하고 픽셀 보정이 너무 과하게 이뤄질 수도 있음.
🔹 블록 크기 선택 기준
✅ 비디오 품질과 연산 속도의 균형
- 5×5 크기는 일반적으로 픽셀 정렬 보정을 하면서도 연산량을 적절히 유지하는 기준점으로 사용됨.
✅ 영상 해상도에 따라 크기 조정 가능 - 고해상도(4K, 8K)에서는 7×7 또는 9×9 블록을 사용할 수도 있음.
✅ 장면 특성에 따라 적응적(Adaptive) 블록 크기 조정 가능 - 픽셀 정렬 오류가 심한 경우, 더 넓은 검색 범위를 갖는 블록 크기를 사용할 수도 있음.

Leave a comment